
Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements. This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation. The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model. A key innovation here is the design of a compact latent space that can directly utilizes a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs. For instance, CMD can sample a video 7.7x faster than prior approaches by generating a video of 512x1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
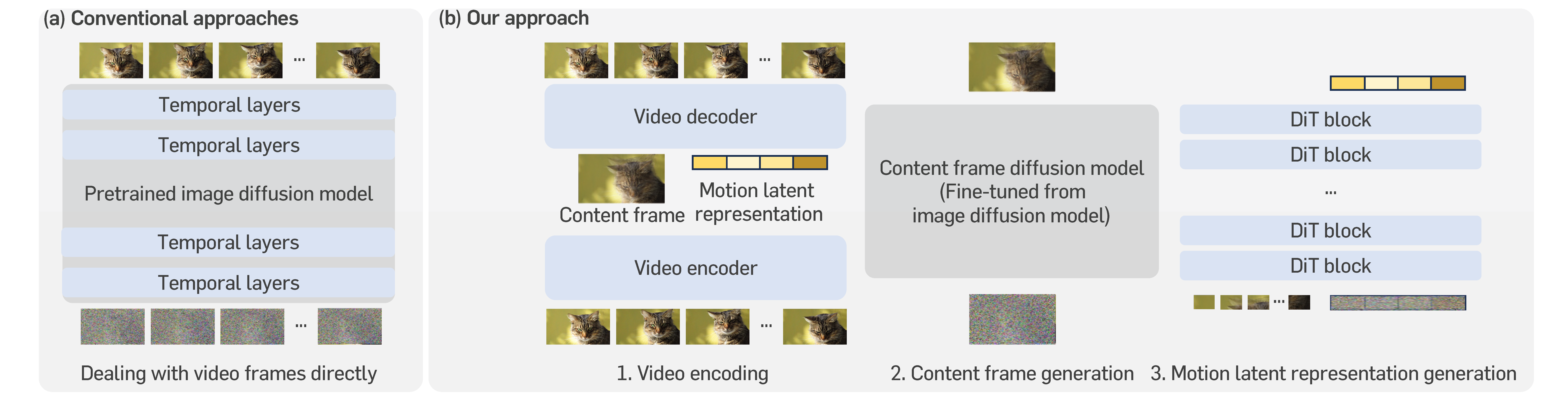
Unlike common approaches that directly add temporal layers in pretrained image
diffusion models for extension, CMD encodes each video as an image-like content
frame and motion latents, and then fine-tunes a pretrained image diffusion model
(e.g., Stable Diffusion) for content frame generation and trains a new lightweight
diffusion model (e.g., DiT) for motion generation.
We introduce content-motion latent diffusion model (CMD), a memory- and computation-efficient latent video DM that leverages visual knowledge present in pretrained image DMs. CMD is a two-stage framework that first compresses videos to a succinct latent space and then learns the video distribution in this latent space. A key difference compared to existing latent video DMs is the design of a latent space that directly incorporates a pretrained image DM. In particular, we learn a low-dimensional latent decomposition into a content frame (like an image) and latent motion representation through an autoencoder. Here, we design the content frame as a weighted sum of all frames in a video, where the weights are learned to represent the relative importance of each frame.
Existing video diffusion models often overlook common contents in video frames (e.g., static background), and accordingly, many spatial layer operations (e.g., 2D convolutions) become unfavorably redundant and tremendous. However, CMD avoids dealing with giant cubic arrays, and thus, redundant operations are significantly reduced, resulting in a computation-efficient video generation framework. In particular, the sampling efficiency is also reflected in sampling time; CMD only requires ~3 seconds with a DDIM sampler using 50 steps, which is 10x faster than existing text-to-video diffusion models.
FLOPs, time (s), and memory (GB) of different methods that sample a 16-frame video with resolution of 512x1024 (i.e., batch size = 1 by default). All values are measured with a single NVIDIA A100 40GB GPU with mixed precision.
CMD requires less memory and computation for training due to the decomposition of videos as two low-dimensional latent variables (content frame and motion latent representation). Notably, CMD shows significantly fewer FLOPs than prior methods: the bottleneck is in the autoencoder (0.77 TFLOPs) and is ~12x more efficient than 9.41 TFLOPs of ModelScope. Note that if one sums up the FLOPs or training time of all three components in CMD, they are still significantly better than existing text-to-video diffusion models. We also note that the training of content frame diffusion models and motion diffusion models can be done in parallel. Thus, the training efficiency (in terms of time) can be further boosted.
FLOPs, sec/step, and memory (GB) of different methods that are trained on 16-frame videos with resolution of 512x512 and batch size of 1. All values are measured with a single NVIDIA A100 80GB GPU with mixed precision. For a fair comparison, we do not apply gradient checkpointing for all models.
|
"Fireworks." |
"A video of the Earth rotating in space." |
"A Teddy Bear skating in Times Square." |
"A clownfish swimming through a coral reef." |
|
"Fire" |
"3D fluffy Lion grinned, closeup cute and adorable, long fuzzy fur, Pixar render." |
"A beautiful Chirstmas tree is rotating." |
"A bigfoot walking in the snowstorm." |
|
"A blue unicorn flying over a mystical land." |
"A Teddy Bear is playing the electric guitar, high definition." |
"A corgi is swimming fastly." |
"A panda playing on a swing set." |
|
"Traffic jam on 2e de Maio avenue, both directions, south of Sao Paulo." |
"Sailboat sailing on a sunny day in a mountain lake, highly detailed." |
"Albert Einstein washing dishes." |
"Robot dancing in Times Square." |
|
"Red wine is poured into a glass." |
"A shark swimming in clear Carribean ocean." |
"An astronaut dances in the dessert." |
"A knight riding on a horse through the countryside." |
|
"An Iron Man surfing in the sea." |
"Blue sky clouds timelapse 4k time lapse gib white clouds cumulus growing cloud formation sunny weather background." |
"Pouring latte art into a silver cup with a golden spoon next to it. high resolution." |
"Close up of grapes on a rotating table. High Definition." |
|
"A big palace is flying away, anime style, best quality." |
"A Goldendoodle playing in a park by a lake, high resolution." |
"Beautiful flag is waving." |
"A Golden Retriever has a picnic on a beautiful tropical beach at sunset, high resolution." |

Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
Sihyun yu, Weili Nie, De-An Huang, Boyi Li, Jinwoo Shin, Anima Anandkumar
International Conference on Learning Representations (ICLR), 2024
@inproceedings{yu2024cmd,
title={Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition},
author={Sihyun Yu and Weili Nie and De-An Huang and Boyi Li and Jinwoo Shin and Anima Anandkumar},
booktitle={International Conference on Learning Representations},
year={2024}
}